��ƪ��Ҫ�v�����ʹ��TXF(TensorFlow Extended) library��ML���w�ܘ����K����CI/CD߀��CT��ԭ�t��ʹ�� Cloud Build�ckubeflow pipeline��
�@ƪ�����m���ϣ���{���� CI/CD practices�Ԍ� ML ��Q�����w�Ƶ� Google Cloud �ϵ����a�h�����Kϣ�������_���� ML pipeline��quality��maintainability��adaptability���Y�ϿƌW�Һ� ML ���̎���
�@ƪ���������µ�һЩ���}:
MLOps
Ҫ�� ML ϵ�y���ϵ�production�h���У��҂���Ҫ����(orchestrate) ML pipeline�еIJ��E�� ���⣬�҂���Ҫ�Ԅӈ���pipeline�Գ��mӖ��ģ�͡� Ҫ�Lԇ�µ��뷨��features���҂���Ҫ��pipeline��new implementations�В��� CI/CD practices�� ���²��� ML �е� CI/CD �� CT ����һЩHigh level��overview��
ML pipeline���Ԅӻ�
��ijЩuse cases�У�Ӗ������C�Ͳ��� ML ģ�͵��ք��^���䌍������ˡ� ����҂��ĈFꠃH����ׂ���������Ӗ���������ĵ� ML ģ�ͣ����@�N�քӷ���߀����Ч�� Ȼ�����ڌ��`�У�ģ���ڬF�������в���r�������������������o���m���h���DŽӑB�Ļ��ܿ�Ҋ�Y�τӑB��׃����
�����҂��� ML ϵ�y�m���@Щ׃�����҂���Ҫ�������� MLOps ���g��
�҂������Ԅӻ� ML production pipeline����ʹ�����Y������Ӗ���҂���ģ�͡� �҂�����by on demand��on schedule���������Y�ϵĿ����ԡ�ģ��Ч���½����Y�ϽyӋ���Ե��@��׃�����������l���ȁ��|�lpipeline��
CI/CD pipeline�c CT pipeline�ı��^
���Y�ϵĿ�����������Ӗ�� ML ģ�͵�һ���|�l�c�� ML pipeline�� new implementation������ new model architecture/feature engineering/hyperparameters���Ŀ������������� ML pipeline����һ����Ҫ�|�l���ء� ML pipeline���@�Nnew implementation�䮔ģ���A�y���յ��°汾�����磬�������online serving�� REST API ��microservice���ɷN��r�ą^�e���£�
����ʹ�����Y��Ӗ���µ� ML ģ�ͣ���Ҫ����֮ǰ����� CT pipeline�� ���]�в����µ�pipeline��component�� ��pipeline��ĩ��ֻ�ṩ�µ��A�y���ջ���Ӗ����ģ�͡�
����ʹ��new implementationӖ���µ� ML ģ�ͣ���Ҫͨ�^ CI/CD pipeline�����µ�pipeline��
Ҫ���ٲ����µ� ML pipeline���҂���Ҫ�O�� CI/CD pipeline�� �@��pipelineؓ؟��new implementation�ǿ��ÁK������춸��N�h��������development, test, staging, pre-production, canary,production���r�ԄӲ����µ� ML pipeline��component��
�Dչʾ�� CI/CD pipeline�� ML CT pipeline֮�g���P�S��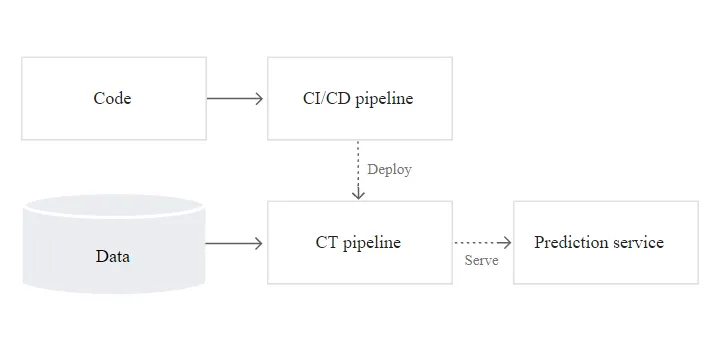
�ψD��pipeline��output����:
�OӋһ�� TFX-based��MLϵ�y
���²���ӑՓ���ʹ�� TFX�OӋһ������ʽ�� ML ϵ�y���� ML ϵ�y�O�� CI/CD pipeline�� �����ж�N���� ML ģ�͵Ŀ�ܣ��� TFX ��һ�����ϵ� ML ƽ̨������_�l�Ͳ���production ML ϵ�y�� TFX pipeline�nj��F ML ϵ�y��һϵ��components�� �@��TFX pipeline����ɔUչ�ĸ����� ML �΄ն��OӋ�� �@Щ�΄հ�����ģ��Ӗ������C��serving inference�Ͳ�������� TFX��key libraries���£�
TFX ML system overview
�D�ɸ��N TFX libraries���ϳ�ML ϵ�y��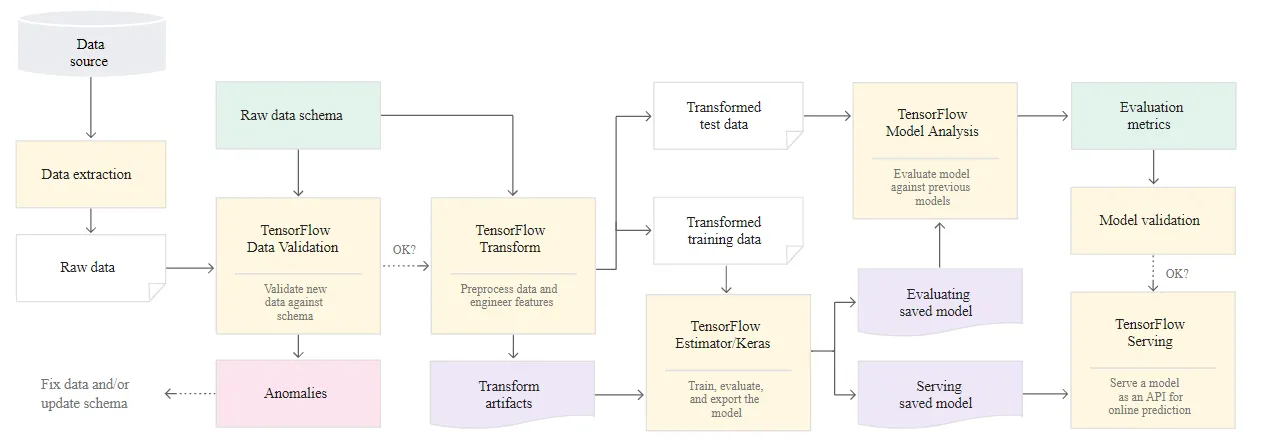
�ψD�@ʾ��һ�����͵�TFX-based ML system. ���µIJ��E�f���������քӻ����Ԅӵ�pipeline:
Google Cloud�� TFX ML system
�����a�h���У�system component����ڿɿ���ƽ̨�ϴ�Ҏģ�\���� �D�@ʾ�� TFX ML pipeline��ÿ�����E���ʹ�� Google Cloud �ϵ�Ӛ�ܷ����\�����Ķ��_����Ҏģ�������ԡ��ɿ��Ժ�Ч�ܡ�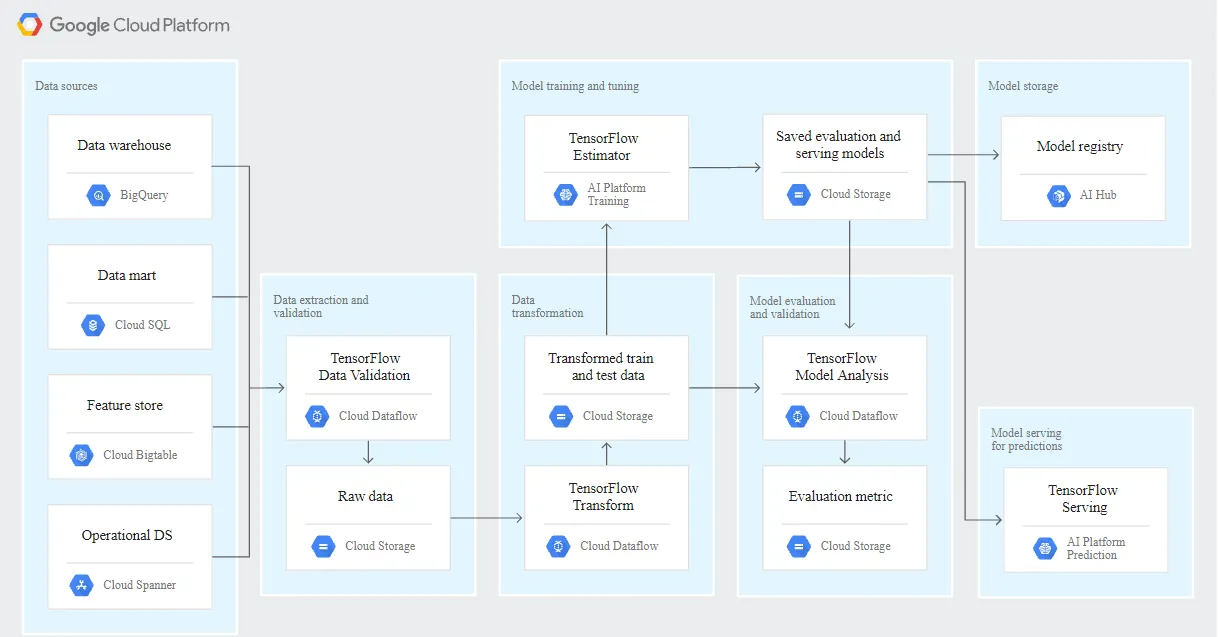
�±�������GCP�ķ��Ռ������wTFX-based ML system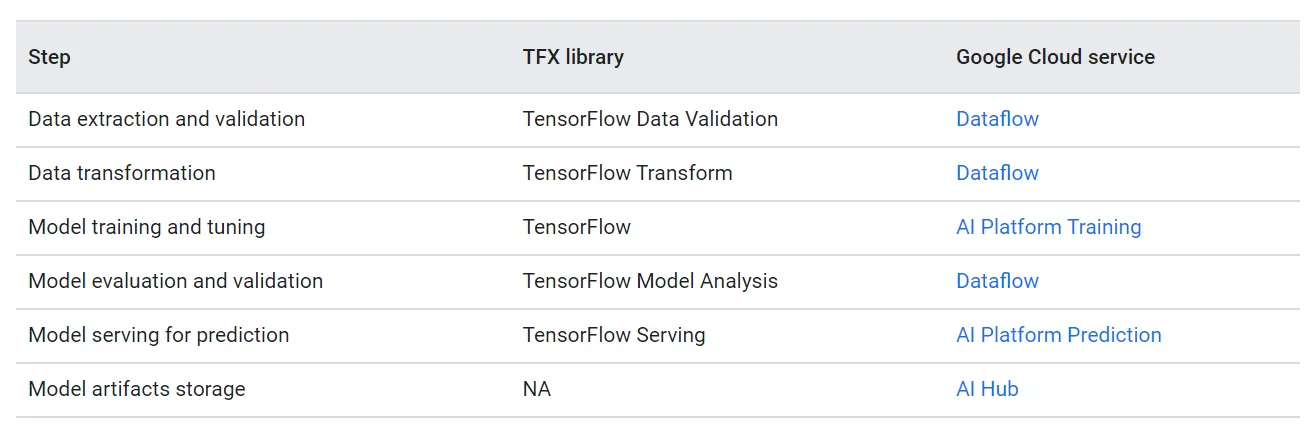
Dataflow ��һ�ȫӚ�ܡ�serverless�ķ��գ������ Google Cloud �ϴ�Ҏģ�\���� Apache Beam pipeline�� Dataflow ��추Uչ�������̣�
Cloud Storage ��һ�N���binary large objects��high available��durable storage�� Cloud Storage Ӛ���� ML pipeline�����^���Юa����artifacts���������£�
AI Hub ��һ����I�ȼ���Ӛ��repository�����discovering��sharing��reusing��AI�� ML �Y�a�� Ҫ�惦���^Ӗ������C��ģ�ͼ������Pmetadata���҂�����ʹ�� AI Hub ����model registry��
AI Platform ��һ�Ӛ�ܷ��գ���춴�ҎģӖ���ͷ��� ML ģ�͡� AI Platform Training ���H֧Ԯ TensorFlow��Scikit-learn �� XGboost ģ�ͣ�߀֧Ԯʹ�ÿ͑��Լ����������κο����implement��ģ�͡� ���⣬߀�ṩ�ɔUչ�ġ����ؐ�~˹(Bayesian)������hyperparametering tuning�� ���^Ӗ����ģ�Ϳ���������� REST API ��microservice���� AI Platform Prediction��
ʹ�� Kubeflow pipeline ���� ML system
��ƪ��B�t������OӋ��� TFX ��MLϵ�y���Լ������ Google Cloud �ϴ�Ҏģ�\��ϵ�y��ÿ��component�� ���ǣ��҂���Ҫһ��orchestrator�팢ϵ�y���@Щ��ͬcompoenent�B����һ�� orchestrator������\��pipeline���K�������õėl���Ԅӏ�һ�����E������һ�����E�� ���磬����u��ָ�˝M���ѽ����õ�thresholds���t���õėl��(condition)���ܕ���ģ���u�����E֮�����ģ���Ͼ��IJ��E�� ���� ML pipeline���_�l�����a�A�ζ�����Ч�ģ�
ML�c Kubeflow pipeline
Kubeflow ��һ���_Դ��Kubernetes ��ܣ�����_�l���\��portable�� ML workload�� Kubeflow Pipelines ��һ�� Kubeflow service�������҂�compose��orchestrate���Ԅӻ� ML ϵ�y������ϵ�y��ÿ��component�������� Kubeflow��Google Cloud ������cloud platform���\�С� Kubeflow Pipelines ƽ̨���������ݣ�
�����f����ν���һ��kubeflow pipeline:
һ�M�������� ML tasks��component�� pipeline component��һ�N�����Docker image��self-contained code�� component��take input arguments, produces output files,���K��pipeline�Ј���һ��step��
ML tasks����Ҏ����ͨ�^ Python DSL�����x�� workflow��topology��ͨ�^��upstream step��output�B�ӵ�downstream step��input�����x�ġ� pipeline definition�е�һ��step���{��pipeline�е�һ��component�� ���}�s��pipeline�У�component����ѭ�h���ж�Σ�Ҳ�����Зl���؈��С�
һ�Mpipeline input parameters����values���f�opipeline��component������filter�Y�ϵĘ˜��Լ�pipeline�a����artifacts�Ĵ惦λ�á�
�����@ʾ��һ�����ε� kubeflow pipelines�D��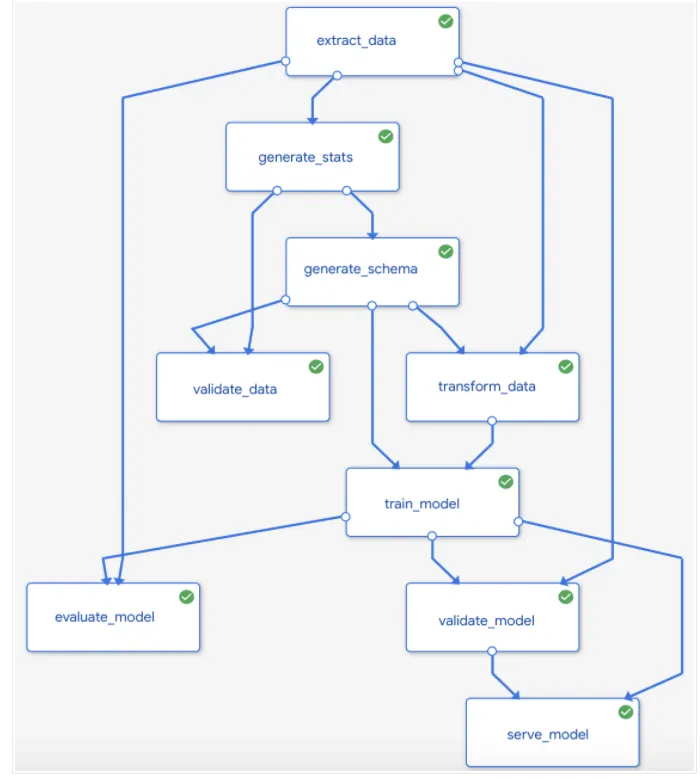
Kubeflow Pipeline components
���Ҫ��pipeline���{�õ�component���҂���Ҫ����һ�� component op�� �҂�����ʹ�����·���create component op��
���Flightweight Python component���@��component����Ҫ�҂���ÿ�ε�code change�����µ�container image���K����Ҫ����Notebook�h���еĿ���iteration�� �҂�����ʹ�� kfp.components.func_to_container_op function�� Python function����lightweight component��
Create reusable component���@������Ҫ���҂���component�� component.yaml �а���component specification�� component specification�څ�����Ҫ���е� Docker container image URL ��output������ Kubeflow pipeline��component�� component ops����pipeline compilation���gʹ�� Kubeflow Pipelines SDK �е� ComponentStore.load_components function�� component.yaml �Ԅӽ����ġ� reusable�� component.yaml specification���Թ����� AI Hub���Ա��ڲ�ͬ�� Kubeflow Pipelines project���M�нM�ϡ�
ʹ��predefined GCP component��Kubeflow Pipelines �ṩ�A���x��component���@Щcomponentͨ�^�ṩ����ą����� GCP �ψ��и��NӚ�ܷ��ա� �@Щcomponent�Ɏ����҂�ʹ�� BigQuery��Dataflow��Dataproc �� AI Platform �ȷ��Ո���task�� �@Щ�A���x�� Google Cloud componentҲ���� AI Hub ��ʹ�á� �cʹ��reusable component��ƣ��@Щcomponent ops��ͨ�^ ComponentStore.load_components �����A���x��component specification�Ԅӽ����ġ� �����A���xcomponent������� Kubeflow ������ƽ̨�Ј������I��
�҂�߀����ʹ�� TFX Pipeline DSL �cTFX component�� TFX component���b��metadata functionality�� Driver ͨ�^��ԃmetadata store��executor�ṩmetadata�� Publisher����executor�ĽY���K����惦��metadata�С� �҂�߀���Ԍ��F�cmetadata������ͬintegration���Զ��xcomponent�� TFX �ṩ��һ��CLI���Ɍ�pipeline�� Python code���g�� YAML file�K���� Argo workflow�� Ȼ���҂����Ԍ��@��file submit�� Kubeflow Pipelines��
�D�@ʾ���� Kubeflow Pipelines �У�containerized task����{������services������ BigQuery jobs��AI Platform���ց�ʽ)Ӗ�����I�� Dataflow jobs��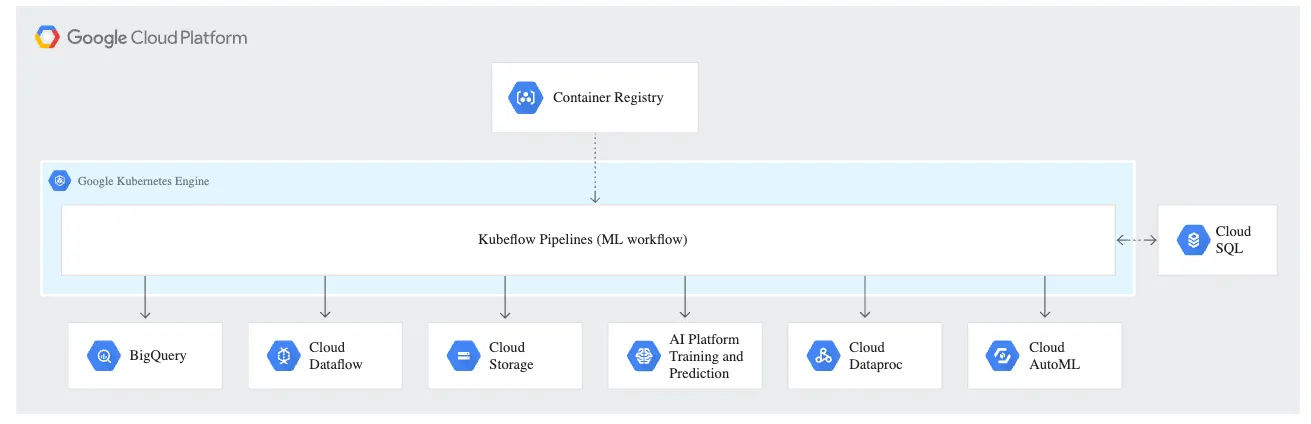
Kubeflow Pipelines ���҂�ͨ�^��������� GCP services�����ź��Ԅӻ�production ML pipeline�� �ψD�У�Cloud SQL ���� Kubeflow Pipelines �� ML metadata store��
Kubeflow Pipelines component���H����� GCP �ψ����c TFX ���P��services�� �@Щcomponent���Ԉ����κ��cdata���P��compute���P�ķ��գ�������� Dataproc for SparkML jobs��AutoML �c�������P��compute workloads��
Kubeflow Pipelines �е�containerizing tasks���������c��
�|�l�cscheduling Kubeflow Pipelines
���҂��� Kubeflow pipeline�������a�h���r���҂���Ҫ�Ԅӻ�����У����wȡ�Q� �҂��ڡ�ML�c Kubeflow pipeline��������ӑՓ�Ĉ�����
Kubeflow Pipelines �ṩ��һ�� Python SDK ���Ԍ���ʽ�ķ�ʽ����pipeline�� kfp.Client class������춽���experiments�Լ�������\��pipeline�� API�� ͨ�^ʹ�� Kubeflow Pipelines SDK���҂�����ʹ������service�{�� Kubeflow Pipelines��
Kubeflow Pipelineͬ�rҲ�ЃȽ���scheduler���܁�ؓ؟���}�Ե�pipelines.
�� Google Cloud�O�� CI/CD
Kubeflow Pipelines ʹ�҂��܉����漰�������E�� ML ϵ�y������data preprocessing, model training and evaluation, model deployment�� ���Y�ϿƌW̽���A�Σ�Kubeflow Pipelines ����춌�����ϵ�y�M�п��ٌ� �����a�A�Σ�Kubeflow Pipelines ʹ�҂��܉�������Y���Ԅӈ���pipeline��train or retrain ML ģ�͡�

 iThome�F��ِ
iThome�F��ِ
IT���æ
 ����
����
